
Variable-Length Sequences in TensorFlow Part 1: Optimizing Sequence Padding
We analyze the impact of sequence padding techniques on model training time for variable-length text data.

Text data comes in different shapes and sizes: sequences of characters, sequences of words, sequences of sentences, and so on. This lack of uniformity has implications when working with machine learning (ML) algorithms that process text sequences in batches. The batches need to have uniform-length sequences, however, text sequences are often of varying lengths.
In this three-part series, we will review different strategies to handle variable-length sequences in TensorFlow with a focus on performance, and discuss the pros and cons of each strategy along with their implementations in TensorFlow.
We have successfully applied some of these strategies to the large-scale data here at Carted and have seen significant timing improvements as a result. We hope you’ll be able to apply them to your own projects as well.
This discussion is made available as a three part series:
- Part 1 (this article): learn how to process variable-length text data with simpler models consisting of fully-connected layers and GRU units.
- Part 2: explore more complex models like BERT and discuss strategies for handling variable-length text data for that setup.
- Part 3: continue our discussion of handling variable-length text sequences for a BERT variant available on TensorFlow Hub (which is better for representing whole sentences).
We’ll assume that the reader has intermediate-level knowledge of TensorFlow, especially tf.data, and beginner-level knowledge of NLP.
General setup
We’ll be using this dataset from Kaggle which provides a text classification problem. Specifically, given a description of a movie, we need to predict its genre. Each description consists of multiple sentences and there are 27 unique genres (such as action, adult, adventure, animation, biography, comedy, etc.).
As a disclaimer, our focus is on designing efficient data pipelines for handling variable-length text sequences that can help us reduce compute waste. For completeness, we will also show how to use these pipelines to train text classification models.
You can find the full working code we’ll be discussing in this GitHub repository. For brevity, we won't cover the entire codebase and instead focus on the non-trivial bits.
Designing the data pipeline
In NLP tasks, it’s common practice to first tokenize the input sequences. The tokenized sequences are typically batched together and are then provided to a model (such as a neural network) for training.
Recall that for batching, we need to have all the sequences in a given batch be of uniform length. To do that, we either (1) pad the sequences that are shorter than a given length or (2) truncate the sequences that are bigger than the given length. The question is how do we decide this length? We have several options:
- We decide on a global maximum sequence length based on the sequence length characteristics of the training data. Consider the following statistical summary.
We can see that the maximum sequence length is 1829 and pad all sequences to this length. To reduce the overall computation time, we could also use 121 since 75% of the sequences have this length — but this may affect the downstream model training performance.
| Metric | Value |
|---|---|
| count | 54214 |
| mean | 101.906426 |
| std | 76.579309 |
| min | 6 |
| 25% | 55 |
| 50% | 79 |
| 75% | 121 |
| max | 1829 |
- Another option is to calculate the maximum sequence length for a given batch of sequences and perform the padding based on that value.
We will consider both these options and compare their performance in terms of total model training time. The second option appears to offer the advantage of reduced compute waste — given that within a particular batch there will be less variance in sequence length as compared to the global set of sequences — and therefore less wasted compute for a given batch.
Particulars of the data input pipeline
Let’s see these concepts expressed in code. TensorFlow provides a whole array of preprocessing layers for handling various data modalities such as text, images, video, and more. Among these layers, TextVectorization and StringLookup are of particular interest to us. The first one will allow us to tokenize the movie descriptions while the second one will allow us to integer-encode the labels (the movie genres).
Both of these layers require a fixed, predetermined set of words — a vocabulary — to perform tokenization and encoding. We can either supply a precomputed vocabulary or we can call the adapt() method of these layers to compute the vocabulary from the data itself. In code, it looks as follows:
# Compute the vocabulary from data.
text_vectorizer = keras.layers.TextVectorization()
text_vectorizer.adapt(train_df["summary"])
# Supply a precomputed vocabulary during initialization.
label_encoder = keras.layers.StringLookup(vocabulary=train_df["genre"].unique())
# Investigate the vocabulary.
print(label_encoder.get_vocabulary())The text vectorization layer will map each movie description to integer sequences. It will take care of the following:
- Text normalization with lower-case letters and punctuation stripping.
- Splitting based on whitespace.
Additional details about the layer are available here.
With these two preprocessing layers set up we can now prepare our data input pipeline:
def preprocess_single_row(summary, label):
summary = text_vectorizer(summary)
label = label_encoder(label)
return summary, label
# `AUTO` is aliased as `tf.data.AUTOTUNE`
def prepare_dataset(dataframe):
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["summary"].values, dataframe["genre"].values)
)
dataset = dataset.map(preprocess_single_row, num_parallel_calls=AUTO)
dataset = dataset.padded_batch(BATCH_SIZE)
return dataset.prefetch(AUTO)Notice the use of padded_batch(). It takes input as a batch of sequences and will pad them with respect to the maximum sequence length within the batch. As a sanity check, we can analyze the batch-wise maximum sequence lengths:
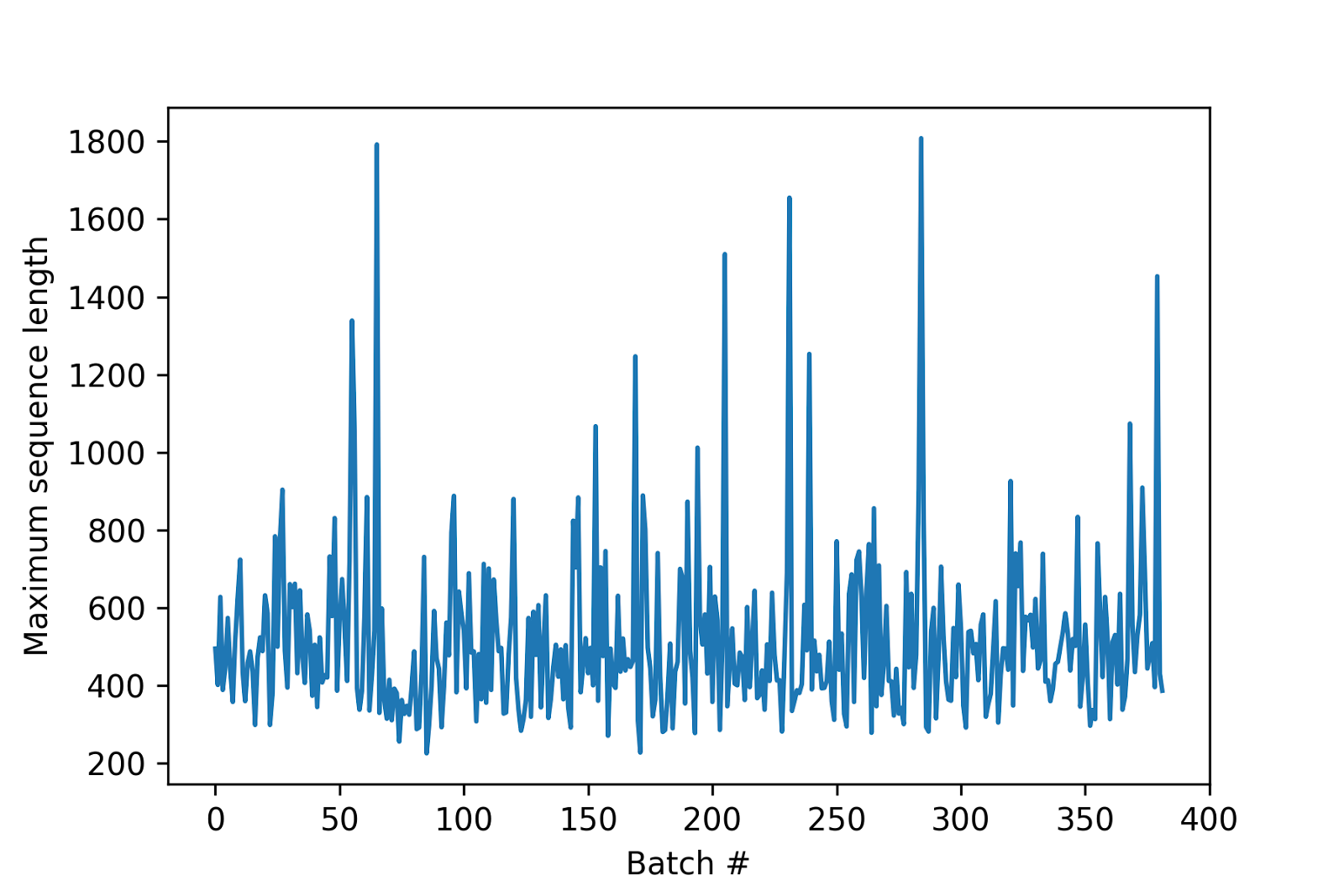
As shown in the chart, most batches have a much smaller maximum sequence length than the global maximum length — supporting our choice to use variable length padding per-batch.
We can compare this approach to the conventional batch() method, where a global maximum sequence length is used.
First, the initialization of the TextVectorization layer would change:
text_vectorizer = keras.layers.TextVectorization(output_sequence_length=max_seqlen)
text_vectorizer.adapt(train_df_new["summary"])max_seqlen is 1829 in this case. This initialization of text_vectorizer will first tokenize the sequences and will then pad them to the length set to output_sequence_length. Since all the tokenized sentences will now have the same length, we can call batch().
Training models with and without fixed-length padding
Now that we’ve prepared our sequences, we can begin training our model. For the purpose of this article, we’ll use a simple model which can be constructed like so:
def make_model():
inputs = keras.Input(shape=(None,), dtype="int64")
x = keras.layers.Embedding(
input_dim=text_vectorizer.vocabulary_size(),
output_dim=16,
)(inputs)
x = keras.layers.Bidirectional(keras.layers.GRU(8))(x)
x = keras.layers.Dense(512, activation="relu")(x)
x = keras.layers.Dense(256, activation="relu")(x)
outputs = keras.layers.Dense(label_encoder.vocabulary_size(), activation="softmax")(
x
)
model = keras.Model(inputs, outputs)
return modelAgain, our aim with this article is to focus on training speed rather than training a state-of-the-art model. Training the above model with fixed (global) and variable (batch-wise) padding length leads to the following result:
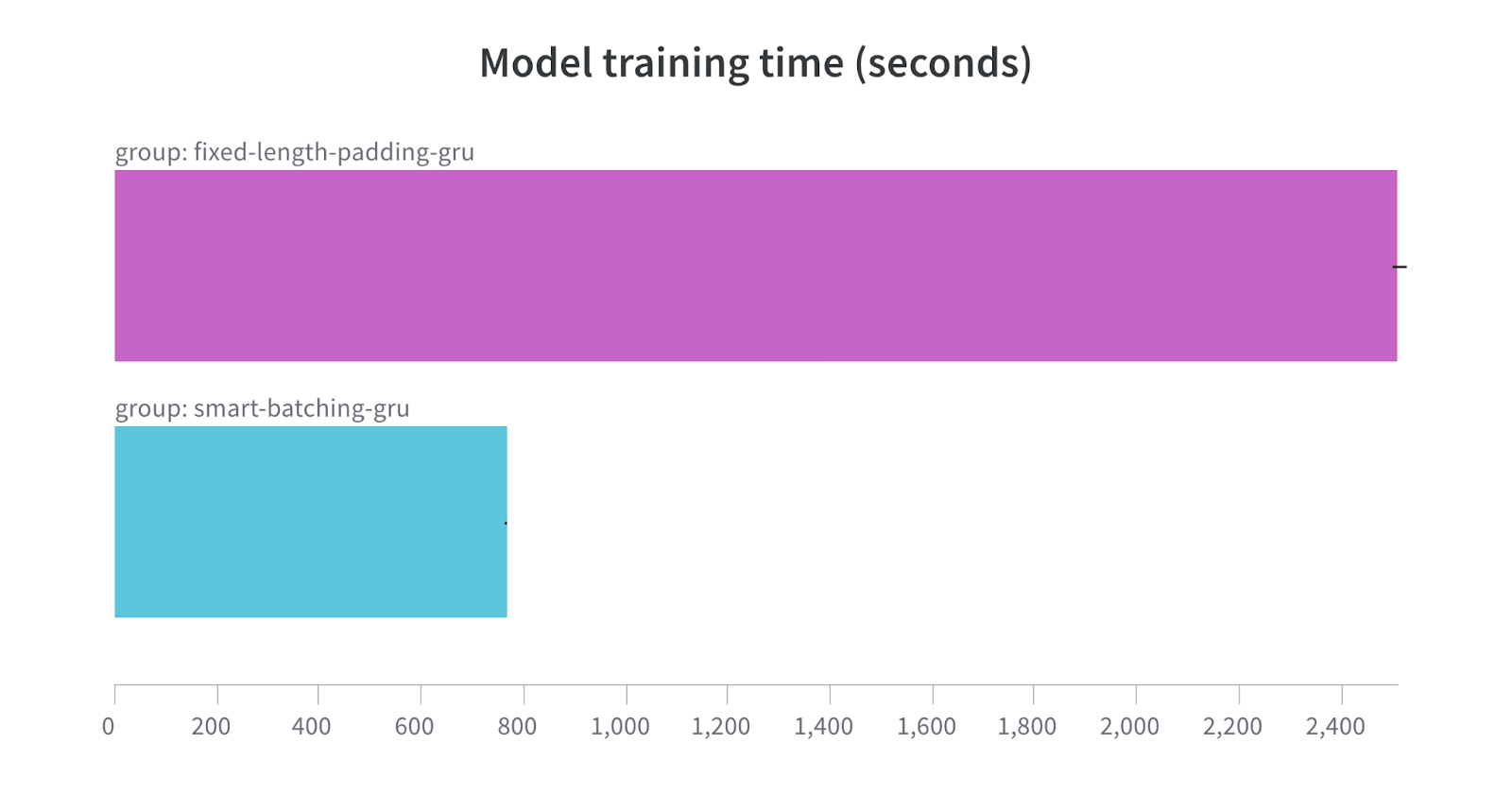
Even with significantly improved model training time, we don’t notice any drop in model performance:
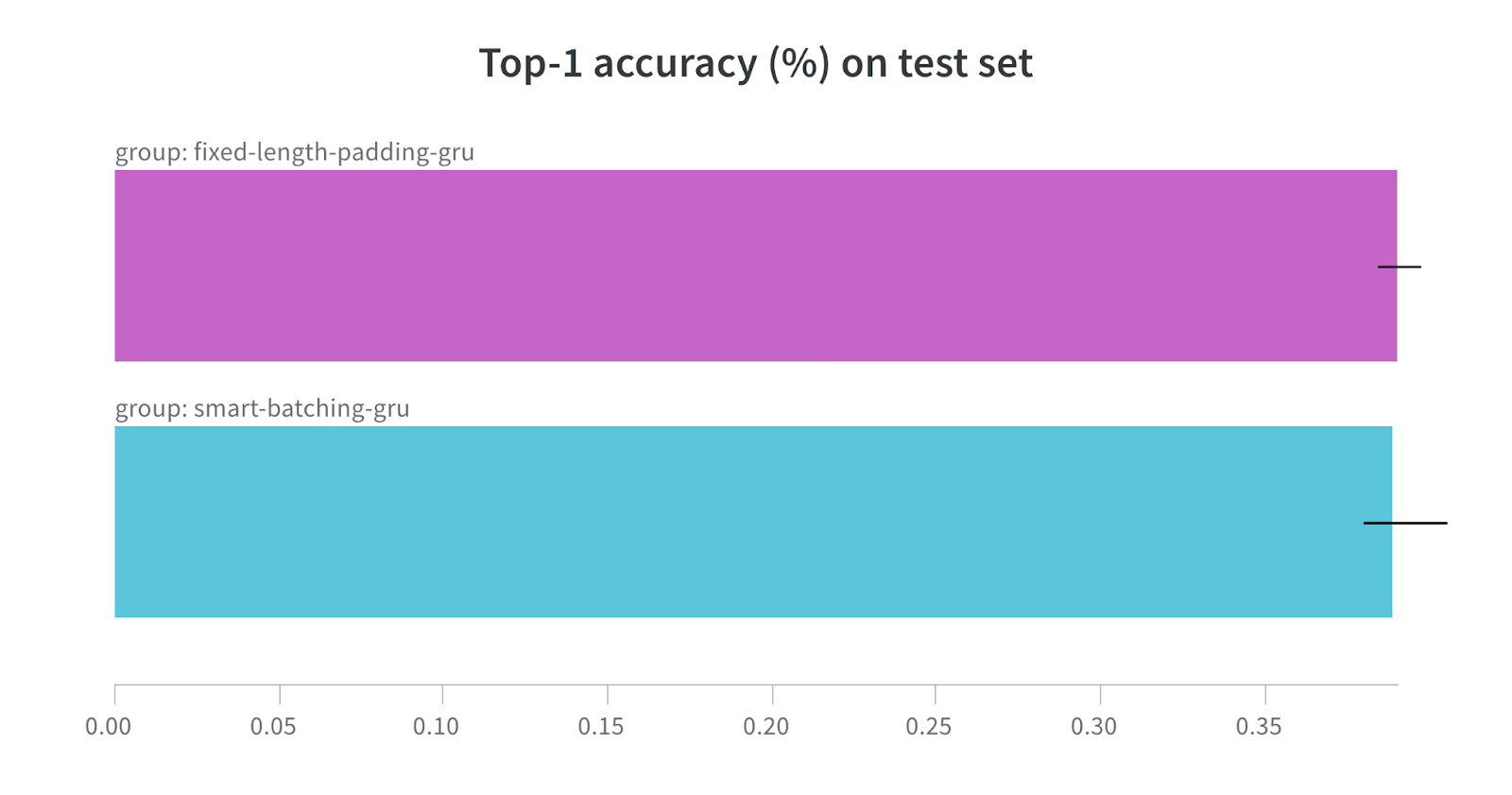
Achieving the same accuracy but with a much shorter training time is an undoubted success, and demonstrates that variable-length sequence padding is the preferred approach when handling text data of varying sequence lengths.
The results reported above were averaged across five individual runs; a self-contained notebook is available here if you would like to reproduce the results.
What’s next?
That’s all for Part 1, where we discussed the impact on model training time of variable-length versus fixed-length sequence padding. We hope you’ll be able to apply the simple recipe we discussed for dealing with variable-length text sequences in your own projects.
In Part 2 of this series, we will work with a BERT encoder and discuss the techniques needed to process text sequences with variable lengths in that context.